一、部署文档
1、部署环境
- 192.168.2.100 admin
- 192.168.2.101 node1
- 192.168.2.102 node2
- 192.168.2.103 node3
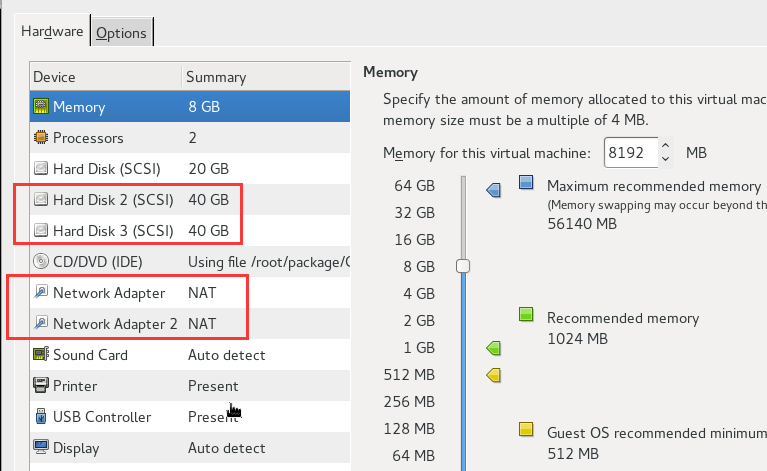
admin为部署节点,所有节点都为具备两个网卡,三个硬盘,其中两个数据盘作为Ceph的OSD盘。
两个网卡分别对应两套网络:192.168.2.0/24和10.10.10.0/24,选择192.168.2.0/24作为Ceph的管理网络(即public network),10.10.10.0/24作为存储网络(即cluster network)。
生产环境中,为避免Mon节点的单点故障,任选三个节点安装Ceph Monitor服务(尽量选择不同机架上节点)。
默认关闭防火墙和禁用SELinux,具体脚本可参考这里。
2、配置过程
2.1 安装源设置
|
1 2 3 |
# yum install -y yum-utils && yum-config-manager --add-repo \ https://dl.fedoraproject.org/pub/epel/7/x86_64/ && yum install \ --nogpgcheck -y epel-release && rpm --import /etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-7 |
添加ceph安装源配置文件,模版如下。
|
1 2 3 4 5 |
# cat /etc/yum.repos.d/ceph.repo [ceph-noarch] name=Ceph noarch packages baseurl=http://download.ceph.com/rpm-jewel/el7/noarch gpgcheck=0 |
如果安装部署多节点的生产环境,建议将download.ceph.com下的镜像到本地,采用本地安装源安装效率会高很多。
2.2 时间同步设置
所有节点修改为东八区时区,并安装chrony
|
1 2 |
# cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime # yum install -y chrony |
修改chrony配置,所有节点时间与admin节点同步。
其他将时间同步主机设为admin,例如:
|
1 2 |
# vim /etc/chrony.conf server admin burst |
admin主机可以根据需要设置所参考的时间同步服务器,如果参考其他联网服务器,指定服务器,也可以保持默认的时间同步主机即可,如:
|
1 2 |
# vim /etc/chrony.conf server 0.centos.pool.ntp.org iburst |
注意:如果是离线环境,无法访问外网时间同步服务器,需要进行如下配置
|
1 2 3 4 5 6 7 8 |
# vim /etc/chrony.conf ## 取消其他时间同步服务器设置 #server 0.centos.pool.ntp.org iburst #server 1.centos.pool.ntp.org iburst #server 2.centos.pool.ntp.org iburst #server 3.centos.pool.ntp.org iburst ## 打开此选项 local stratum 10 |
配置完成后,重启服务,并查看状态,确保其他节点的时间同步主机为同一个。
|
1 2 3 |
# systemctl enable chronyd.service # systemctl start chronyd.service # chronyc sources |
2.3 SSH配置
利用root用户安装,不用配置sudo权限,直接配置SSH到其他节点即可
|
1 2 |
# ssh-keygen # ssh-copy-id node1 |
2.4 存储集群部署
安装ceph部署工具ceph-deploy
|
1 2 3 |
# yum install -y ceph-deploy # ceph-deploy --version 1.5.25 |
在部署节点上创建临时部署文件夹,并进入该目录,
|
1 2 |
# mkdir my-cluster # cd my-cluster |
利用ceph-deploy执行安装操作,
|
1 |
# ceph-deploy new admin |
当前目录下会生成一个 Ceph 配置文件ceph.conf 、一个 monitor 密钥环ceph.mon.keyring和一个日志文件ceph-deploy-ceph.log:
修改配置文件,指定mon节点,存储网络和数据副本个数,默认副本数为3个。
|
1 2 3 4 5 6 7 8 9 10 |
# cat /etc/ceph/ceph.conf [global] fsid = 5f29c309-4b37-4e94-b21e-b03045c45e31 mon_initial_members = admin,node1,node2 mon_host = 192.168.2.100,192.168.2.101,192.168.2.102 auth_cluster_required = cephx auth_service_required = cephx auth_client_required = cephx osd pool default size = 3 cluster network = 10.10.10.0/24 |
安装ceph
|
1 |
# ceph-deploy install admin node1 node2 node3 |
初始化monitor,执行完成后在本文件夹会多出密钥环:ceph.bootstrap-mds.keyring、ceph.bootstrap-osd.keyring、ceph.bootstrap-rgw.keyring、ceph.client.admin.keyring。
|
1 |
# ceph-deploy mon create-initial |
添加OSD盘(也可以添加本地目录,具体可参考官网),这里直接添加数据盘,
首先查看本地数据盘设备:
|
1 2 3 4 5 6 7 8 9 10 |
# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 20G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 19G 0 part ├─cl-root 253:0 0 17G 0 lvm / └─cl-swap 253:1 0 2G 0 lvm [SWAP] sdb 8:16 0 40G 0 disk sdc 8:32 0 40G 0 disk sr0 11:0 1 1024M 0 rom |
可以看到本地的数据盘设备为/dev/sdb和/deb/sdc,
|
1 2 |
# ceph-deploy osd prepare admin:sdb admin:sdc node1:sdb node1:sdc node2:sdb node2:sdc node3:sdb node3:sdc # ceph-deploy osd activate admin:sdb1 admin:sdc1 node1:sdb1 node1:sdc1 node2:sdb1 node2:sdc1 node3:sdb1 node3:sdc1 |
或者直接利用两者的组合命令
|
1 |
# ceph-deploy osd create admin:sdb admin:sdc node1:sdb node1:sdc node2:sdb node2:sdc node3:sdb node3:sdc |
用 ceph-deploy 把配置文件和 admin 密钥拷贝到管理节点和 Ceph 节点,这样你每次执行 Ceph 命令行时就无需指定 monitor 地址和 ceph.client.admin.keyring 了
|
1 |
# ceph-deploy admin admin-node node1 node2 node3 |
检查集群的健康状况
|
1 |
# ceph health |
或
|
1 |
# ceph -s |
等pg全部变为active+clean时即可。
2.5 Ceph文件系统
为了使用CephFS,至少需要创建一个元数据服务器MDS(metadata server),如下:
|
1 |
# ceph-deploy mds create node1 |
如果没有创建文件系统的Pool,ceph-mds@admin.service服务是不会启动的,下面创建文件系统的Pool:
|
1 2 3 4 5 6 |
# ceph osd pool create cephfs_data 256 pool 'cephfs_data' created # ceph osd pool create cephfs_metadata 256 pool 'cephfs_metadata' created # ceph fs new filesystem01 cephfs_metadata cephfs_data new fs with metadata pool 2 and data pool 1 |
查看文件系统
|
1 2 |
# ceph fs ls name: filesystem01, metadata pool: cephfs_metadata, data pools: [cephfs_data ] |
查看MDS状态
|
1 2 |
# ceph mds stat e6: 1/1/1 up {0=node1=up:active}, 1 up:standby |
(1)以内核驱动的方式挂载CephFS到指定目录
|
1 |
# mount -t ceph 192.168.2.100:6789:/ /mnt/mycephfs/ -o name=admin,secretfile=admin.secret |
其中admin.secret文件中内容为 ceph.client.admin.keyring文件所对应的key值。
(2)以用户空间的方式挂载CephFS到指定目录
|
1 2 3 4 5 |
# ceph-fuse -k ceph.client.admin.keyring -m 192.168.2.100:6789 /mnt/mycephfs/ ceph-fuse[13313]: starting ceph client 2017-09-21 00:52:11.089273 7fd6fa07cec0 -1 init, newargv = 0x7fd7045d47e0 newargc=11 ceph-fuse[13313]: starting fuse Aborted (core dumped) |
查看挂载状态:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
[root@admin my-cluster]# df -TH Filesystem Type Size Used Avail Use% Mounted on /dev/mapper/cl-root xfs 19G 9.9G 8.5G 54% / devtmpfs devtmpfs 4.1G 0 4.1G 0% /dev tmpfs tmpfs 4.1G 87k 4.1G 1% /dev/shm tmpfs tmpfs 4.1G 9.5M 4.1G 1% /run tmpfs tmpfs 4.1G 0 4.1G 0% /sys/fs/cgroup /dev/sda1 xfs 1.1G 298M 766M 28% /boot tmpfs tmpfs 819M 17k 819M 1% /run/user/42 tmpfs tmpfs 819M 0 819M 0% /run/user/0 /dev/sdc1 xfs 38G 41M 38G 1% /var/lib/ceph/osd/ceph-0 /dev/sdb1 xfs 38G 43M 38G 1% /var/lib/ceph/osd/ceph-2 ceph-fuse fuse.ceph-fuse 301G 332M 301G 1% /mnt/mycephfs |
2.6 Ceph 块设备
创建块设备镜像
|
1 2 3 4 5 6 7 8 9 10 11 |
# rbd create foo --size 4096 # rbd -p rbd ls foo # rbd -p rbd info foo rbd image 'foo': size 4096 MB in 1024 objects order 22 (4096 kB objects) block_name_prefix: rbd_data.110d238e1f29 format: 2 features: layering, exclusive-lock, object-map, fast-diff, deep-flatten flags: |
将镜像映射到块设备,出错
|
1 2 3 4 5 |
# sudo rbd map foo --name client.admin rbd: sysfs write failed RBD image feature set mismatch. You can disable features unsupported by the kernel with "rbd feature disable". In some cases useful info is found in syslog - try "dmesg | tail" or so. rbd: map failed: (6) No such device or address |
原因是内核不支持一些特性feature,需要禁用,
|
1 2 3 4 5 6 7 8 9 |
# rbd feature disable foo exclusive-lock object-map fast-diff deep-flatten # rbd info foo rbd image 'foo': size 4096 MB in 1024 objects order 22 (4096 kB objects) block_name_prefix: rbd_data.110d238e1f29 format: 2 features: layering flags: |
再次映射到本地块设备:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# sudo rbd map foo --name client.admin /dev/rbd0 # lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 20G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 19G 0 part ├─cl-root 253:0 0 17G 0 lvm / └─cl-swap 253:1 0 2G 0 lvm [SWAP] sdb 8:16 0 40G 0 disk ├─sdb1 8:17 0 35G 0 part /var/lib/ceph/osd/ceph-2 └─sdb2 8:18 0 5G 0 part sdc 8:32 0 40G 0 disk ├─sdc1 8:33 0 35G 0 part /var/lib/ceph/osd/ceph-0 └─sdc2 8:34 0 5G 0 part sr0 11:0 1 1024M 0 rom rbd0 252:0 0 4G 0 disk |
接下来可以正常使用该块设备了,创建文件系统,挂载到目录:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# mkfs.xfs /dev/rbd0 # mkdir /data # mount /dev/rbd0 /data/ # df -TH Filesystem Type Size Used Avail Use% Mounted on /dev/mapper/cl-root xfs 19G 9.9G 8.5G 54% / devtmpfs devtmpfs 4.1G 0 4.1G 0% /dev tmpfs tmpfs 4.1G 87k 4.1G 1% /dev/shm tmpfs tmpfs 4.1G 9.5M 4.1G 1% /run tmpfs tmpfs 4.1G 0 4.1G 0% /sys/fs/cgroup /dev/sda1 xfs 1.1G 298M 766M 28% /boot tmpfs tmpfs 819M 17k 819M 1% /run/user/42 tmpfs tmpfs 819M 0 819M 0% /run/user/0 /dev/sdc1 xfs 38G 41M 38G 1% /var/lib/ceph/osd/ceph-0 /dev/sdb1 xfs 38G 41M 38G 1% /var/lib/ceph/osd/ceph-2 /dev/rbd0 xfs 4.3G 34M 4.3G 1% /data |
取消映射:
|
1 |
# rbd unmap foo |
2.7 Ceph对象存储
安装对象存储网关(Ceph Object Gateway)安装包
|
1 |
# ceph-deploy install --rgw admin |
创建对象存储网关
|
1 |
# ceph-deploy rgw create admin |
修改Ceph配置文件,在 /etc/ceph/ceph.conf追加以下内容,这里的your-node对应安装rgw服务的主机名称,本例对应为admin,不要误解。
|
1 2 |
[client.rgw.your-node] rgw_frontends = "civetweb port=80" |
重启对象存储网关服务
|
1 |
# systemctl restart ceph-radosgw@rgw.admin.service |
测试网关
|
1 2 3 4 5 6 7 8 9 10 |
# curl http://192.168.2.100:80 <!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN"> <html><head> <title>503 Service Unavailable</title> </head><body> <h1>Service Unavailable</h1> <p>The server is temporarily unable to service your request due to maintenance downtime or capacity problems. Please try again later.</p> </body></html> |
TODO
二、部署脚本
设置部署配置信息
|
1 |
# vim 0-set-config.sh |
内容如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
#!/bin/sh ### 设置部署节点主机名和IP,并指定monitor节点 declare -A nodes_map=(["admin"]="192.168.2.100" ["node1"]="192.168.2.101" ["node2"]="192.168.2.102" ["node3"]="192.168.2.103"); declare -A monitors_map=(["admin"]="192.168.2.100" ["node1"]="192.168.2.101" ["node2"]="192.168.2.102"); ### 后期需要增加的计算节点 declare -A additional_nodes_map=(["node4"]="192.168.2.104"); ### 存储节点上OSD数据盘,所有节点数据个数及盘符一致 declare -A blks_map=(["osd01"]="sdb" ["osd02"]="sdc"); ### 设置网络网段信息,分别对应管理网、存储网 public_net=192.168.2.0/24 storage_net=10.10.10.0/24 ### 安装源URL yum_baseurl=http://download.ceph.com/rpm-jewel/el7/noarch #yum_baseurl=ftp://192.168.100.81/pub/download.ceph.com/rpm-jewel/el7/noarch ### 部署节点主机名 deploy_node=admin ### NTP参考主机 ntp_server=admin |
为pssh准备一个包含所有节点IP的hosts文件,脚本gen-hosts.sh
|
1 2 3 4 5 6 7 8 9 10 11 |
#!/bin/sh # # create hosts file for pssh . 0-set-config.sh mkdir hosts > hosts/nodes.txt for ip in ${nodes_map[@]}; do echo "$ip" >> hosts/nodes.txt done; |
安装测试pssh脚本
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
#!/bin/sh # # SSH configuration to others nodes ssh-keygen for host in ${nodes_map[@]}; do ssh-copy-id root@$host done # Install pssh installed=$(rpm -qa|grep "pssh") ### Check pssh is installed if [[ -z "$installed" ]];then yum install -y pssh fi # Test pssh pssh -i -h ./hosts/nodes.txt hostname |
关闭防火强并禁用SELinux,禁用SELinux时需要重启,脚本disable_firewall_selinux.sh会自动提示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
#!/bin/sh # # Disable Firewall and SELinux # if SELinux is enable, it should reboot for ip in ${nodes_map[@]}; do sestatus=$(ssh root@$ip sestatus -v |grep "SELinux status:"|awk '{print $3}') flag=unknown if [ $sestatus = "enabled" ];then echo "${ip}:SELinux is enforce!Reboot now? (yes/no)" read flag else echo "SELinux is disabled!" fi ssh root@$ip /bin/bash << EOF systemctl disable firewalld.service systemctl stop firewalld.service sed -i -e "s#SELINUX=enforcing#SELINUX=disabled#g" /etc/selinux/config sed -i -e "s#SELINUXTYPE=targeted#\#SELINUXTYPE=targeted#g" /etc/selinux/config echo $flag if [ $flag = "yes" ];then echo "Reboot now!" reboot elif [ $flag = "no" ];then echo -e "\033[33mWARNNING:You should reboot manually! \033[0m" fi EOF ssh root@$ip systemctl status firewalld.service|grep Active: ssh root@$ip sestatus -v done; |
Chrony时间同步配置脚本set-chrony.sh
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
#!/bin/sh # # NTP: chrony configuration, # chrony sources will be write in result.log declare nodes_name=(${!nodes_map[@]}) for ((i=0; i<${#nodes_map[@]}; i+=1)); do name=${nodes_name[$i]}; ip=${nodes_map[$name]}; if [[ $name = $deploy_node ]];then echo ""$ip sed -i -e '/server [0 1 2 3].centos.pool.ntp.org/d' /etc/chrony.conf sed -i -e "s#\#local stratum#local stratum#g" /etc/chrony.conf echo "allow "$public_net >>/etc/chrony.conf else ssh root@$ip /bin/bash <<EOF sed -i -e 's#server 0.centos.pool.ntp.org#server '"$ntp_server"'#g' /etc/chrony.conf sed -i -e '/server [0 1 2 3].centos.pool.ntp.org/d' /etc/chrony.conf EOF fi ssh root@$ip systemctl enable chronyd.service ssh root@$ip systemctl restart chronyd.service ssh root@$ip cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime done; pssh -i -h ./hosts/nodes.txt "date +%z" pssh -i -h ./hosts/nodes.txt "chronyc sources" |
卸载并删除之前Ceph安装数据uninstall-ceph-storage-cluster.sh,这个脚本在中途安装失败时需要重新安装时进行手动执行,以便清除上次安装遗留数据。
|
1 2 3 4 5 6 |
#!/bin/sh nodes_name=(${!nodes_map[@]}); ###清理ceph安装数据 ceph-deploy forgetkeys ceph-deploy purge ${nodes_name[@]} ceph-deploy purgedata ${nodes_name[@]} |
重置OSD盘为裸盘脚本ceph-zak.sh,如果重置裸盘后内核未读取最新的磁盘分区表,需要重启节点以便内核读取新的磁盘分区。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
#!/bin/sh nodes_name=(${!nodes_map[@]}); blk_name=(${!blks_map[@]}); ###安装前所有OSD盘重置为裸盘 for ((i=0; i<${#nodes_map[@]}; i+=1)); do name=${nodes_name[$i]}; ip=${nodes_map[$name]}; echo $name:$ip for ((j=0; j<${#blks_map[@]}; j+=1)); do name2=${blk_name[$j]}; blk=${blks_map[$name2]}; ssh root@$ip ceph-disk zap /dev/$blk ssh root@$ip partprobe done done |
安装Ceph存储集群脚本install-configure-ceph-storage-cluster.sh
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 |
#!/bin/sh nodes_name=(${!nodes_map[@]}); blk_name=(${!blks_map[@]}); monitor_name=(${!monitors_map[@]}); ### 获取OSD信息,用于生成并激活OSD osds=""; for host in ${!nodes_map[@]}; do for disk in ${blks_map[@]} do osds=$osds" "$host":"$disk; done done ### 获取Monitor信息,用于生成ceph配置文件 mon_hostname="" mon_ip="" ### set mon nodes for ((i=0; i<${#monitors_map[@]}; i+=1)); do name=${monitor_name[$i]}; ip=${nodes_map[$name]}; if [ $name = $deploy_node ]; then echo $name" already is mon!" else mon_hostname=$mon_hostname","$name mon_ip=$mon_ip","$ip fi done; echo $osds echo $mon_hostname echo $mon_ip mkdir -p /root/my-cluster cd /root/my-cluster rm -rf /root/my-cluster/* ceph-deploy new $deploy_node sed -i -e 's#'"$( cat /root/my-cluster/ceph.conf |grep mon_initial_members)"'#'"$( cat /root/my-cluster/ceph.conf |grep mon_initial_members)$mon_hostname"'#g' /root/my-cluster/ceph.conf sed -i -e 's#'"$( cat /root/my-cluster/ceph.conf |grep mon_host )"'#'"$( cat /root/my-cluster/ceph.conf |grep mon_host )$mon_ip"'#g' /root/my-cluster/ceph.conf echo "public network = "$public_net >> /root/my-cluster/ceph.conf echo "cluster network = "$storage_net >> /root/my-cluster/ceph.conf ceph-deploy install ${nodes_name[@]} ceph-deploy mon create-initial ceph-deploy osd create $osds ceph-deploy admin ${nodes_name[@]} ### Add mon nodes for ((i=0; i<${#monitor_map[@]}; i+=1)); do name=${monitor_name[$i]}; ip=${monitor_map[$name]}; echo "Set $name as a ceph monitor" if [ $name = $deploy_node ]; then echo $name" already is mon!" else cd /root/my-cluster ceph-deploy mon add $name fi done; ### Update ceph.conf ceph-deploy --overwrite-conf config push ${nodes_name[@]} ceph -s |
查看最后结果正常即可。
|
1 2 3 4 5 6 7 8 9 10 |
[root@admin ~]# ceph -s cluster ff757361-0477-4c88-b767-00d47bceb888 health HEALTH_OK monmap e2: 3 mons at {admin=192.168.2.100:6789/0,node1=192.168.2.101:6789/0,node2=192.168.2.102:6789/0} election epoch 6, quorum 0,1,2 admin,node1,node2 osdmap e42: 8 osds: 8 up, 8 in flags sortbitwise,require_jewel_osds pgmap v116: 64 pgs, 1 pools, 306 bytes data, 4 objects 271 MB used, 279 GB / 279 GB avail 64 active+clean |
三、参考文档
http://docs.ceph.com/docs/master/start/
四、源码
https://github.com/zjmeixinyanzhi/Ceph-Storage-Cluster-Deploy-Shells.git


codemore code
~~~~