一、概述
最近用户的机房重启了多次,云平台也因此暂停,云平台自启动脚本的需求随之提上日程。Openstack云平台采用了HA架构部署,底层依赖的服务比较多,云平台重启时所做的工作比较多,故障场景也繁杂,这里先撰写一版比较简单的重启脚本,能够应对一般的服务器重启场景(断电重启、集群正常关闭),主要工作包括连通性检测、消息队列集群启动、Galera数据库集群启动、Openstack服务启动(主要由Pacemaker集群管理)、Ceph集群状态检测和Rest-api服务启动、虚拟机状态恢复、管理系统Web服务器启动等等。当然,实际故障场景比较多,相应的运维流程需要不断总结,本脚本也将会持续更新。
二、详细介绍
1、管理集群连通性检测
check-nodes-connectity.sh,这里主要检测控制节点和网络节点集群是否都已经全部正常启动,直到所有节点都能正常ping通后才进行云平台服务的启动,避免因其他节点比当前节点晚启动时而带来的服务启动错误。这里设置控制节点和网络节点存在一个节点无法连通时,该检测会直接退出。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
#!/bin/sh source /root/CloudPlatformOperations/0-set-config.sh SLEEP_SECOND=2 WHILE_FLAG=0 test_connection(){ while [ $WHILE_FLAG -lt 20 ] do SUCCESS_FLAG=$(ping -c 3 $1|grep "100% packet loss"|wc -l) if [ "${SUCCESS_FLAG}" != "1" ];then echo "`eval date +%Y-%m-%d_%H:%M:%S` [INFO] $1:SUCCESS"| tee -a $log_file break; fi echo -ne "=>\033[s" echo -ne "\033[40;-20H"$((WHILE_FLAG*5*100/100))%"\033[u\033[1D" let WHILE_FLAG++ sleep $SLEEP_SECOND done } check_result(){ SUCCESS_FLAG=$(ping -c 3 $1|grep "100% packet loss"|wc -l) if [ "${SUCCESS_FLAG}" = "1" ];then exit 127 fi } ### 1. check compute nodes for node in ${hypervisor_name[@]} do test_connection $node done ### 2. check networker nodes for node in ${networker_name[@]} do test_connection $node check_result $node done ### 3. check controller nodes for node in ${controller_name[@]} do test_connection $node check_result $node done |
2、消息队列集群启动
check-or-restart-rabbitmq-cluster.sh,当前主要检测Rabbitmq集群运行节点个数和Partitions的情况,三个控制节点全部加入集群并且无partitions的情况下,恢复集群正常。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
#!/bin/sh source /root/CloudPlatformOperations/0-set-config.sh RUNNING_SIZE=$(rabbitmqctl cluster_status|grep running_nodes|awk -F "," '{for(i=1;i<=NF;i++){printf "%s ", $i; printf "\n"}}'|grep controller0|wc -l) PARTITIONS_SIZE=$(rabbitmqctl cluster_status|grep partitions|grep controller|wc -l) ### 1. Check and resume rabbitmq-server service in every nodes if [ "${RUNNING_SIZE}" = "3" -a "$PARTITIONS_SIZE" = "0" ]; then echo "`eval date +%Y-%m-%d_%H:%M:%S` [INFO] Rabbitmq cluster is OK!" | tee -a $log_file exit 0 else ssh controller01 systemctl restart rabbitmq-server ssh controller02 systemctl restart rabbitmq-server ssh controller03 systemctl restart rabbitmq-server fi ### 2. Recheck Galera Status RUNNING_SIZE=$(rabbitmqctl cluster_status|grep running_nodes|awk -F "," '{for(i=1;i<=NF;i++){printf "%s ", $i; printf "\n"}}'|grep controller0|wc -l) PARTITIONS_SIZE=$(rabbitmqctl cluster_status|grep partitions|grep controller|wc -l) ### 1. Check and resume rabbitmq-server service in every nodes if [ "${RUNNING_SIZE}" = "3" -a "$PARTITIONS_SIZE" = "0" ]; then echo "`eval date +%Y-%m-%d_%H:%M:%S` [INFO] Rabbitmq cluster have restarted!"| tee -a $log_file exit 0 else echo "`eval date +%Y-%m-%d_%H:%M:%S` [ERROR] Rabbitmq cluster is error!"| tee -a $log_file exit 127 fi |
3、Galera数据库集群的启动
Galera集群的恢复脚本check-or-recover-galera.sh,该脚本应对的场景已经在《Galera集群恢复的常见七种场景》和《MariaDB Galera集群自动恢复脚本》这两篇博客中详细介绍,这里不再赘述。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 |
#!/bin/sh source /root/CloudPlatformOperations/0-set-config.sh STOP_NODES=(); UUID=$(uuidgen) rm -rf /tmp/GTID_* findBootstrapNode(){ for host in $(cat /tmp/GTID_${UUID}|grep "\-1"|awk '{print $2}') do VIEW_ID=$(ssh ${host} cat /var/lib/mysql/gvwstate.dat|grep view_id|awk '{print $3}') MY_UUID=$(ssh ${host} cat /var/lib/mysql/gvwstate.dat|grep my_uuid|awk '{print $2}') if [ $VIEW_ID = $MY_UUID ];then echo $host break fi done } ### 1. Check mariadb service in every nodes for i in 01 02 03; do FLAG=$(ssh controller$i systemctl status mariadb |grep Active:|grep running|wc -l) if [ "${FLAG}" = "0" ];then echo "`eval date +%Y-%m-%d_%H:%M:%S` [INFO] controller$i is down!" | tee -a $log_file let INDEX=${#STOP_NODES[@]}+1 STOP_NODES[INDEX]=controller$i seqno=$(ssh controller$i cat /var/lib/mysql/grastate.dat|grep seqno:|awk '{print $2}') echo $seqno" "controller$i >> /tmp/GTID_$UUID elif [ "$FLAG" = "1" ];then echo "`eval date +%Y-%m-%d_%H:%M:%S` [INFO] controller$i is up!" | tee -a $log_file else echo "`eval date +%Y-%m-%d_%H:%M:%S` [ERROR] Get the status of controller$i ariadb is error!"| tee -a $log_file exit 127 fi done ### 2. Recover Galera Cluster let CLUSTER_SIZE=3-${#STOP_NODES[@]} if [ "${CLUSTER_SIZE}" = "3" ]; then echo "`eval date +%Y-%m-%d_%H:%M:%S` [INFO] Galera is OK!"| tee -a $log_file elif [ "$CLUSTER_SIZE" = "2" -o "$CLUSTER_SIZE" = "1" ];then echo "`eval date +%Y-%m-%d_%H:%M:%S` [INFO] One or Two MariaDB nodes is down!"| tee -a $log_file ## 2.1 Only start the mariadb service in stopped nodes for node in ${STOP_NODES[@]}; do ssh ${node} systemctl start mariadb done elif [ "${CLUSTER_SIZE}" = "0" ]; then echo "`eval date +%Y-%m-%d_%H:%M:%S` [INFO] All MariaDB nodes is down!"| tee -a $log_file ABNORMAL_SIZE=$(cat /tmp/GTID_$UUID |grep "\-1"|wc -l) ## 2.2 Find the latest state node to bootstrap and start others nodes ## 2.2.1 All three nodes are gracefully stopped if [ "$ABNORMAL_SIZE" = "0" ];then BOOTSTARP_NODE=$(cat /tmp/GTID_$UUID|sort -n -r|head -n 1|awk '{print $2}') echo "`eval date +%Y-%m-%d_%H:%M:%S` [INFO] All three nodes are gracefully stopped!"| tee -a $log_file ## 2.2.2 All nodes went down without proper shutdown procedure elif [ "$ABNORMAL_SIZE" = "1" ];then BOOTSTARP_NODE=$(cat /tmp/GTID_$UUID|grep "\-1"|awk '{print $2}') echo "`eval date +%Y-%m-%d_%H:%M:%S` [INFO] One node disappear in Galera Cluster! Two nodes are gracefully stopped!"| tee -a $log_file elif [ "$ABNORMAL_SIZE" = "2" ];then echo "`eval date +%Y-%m-%d_%H:%M:%S` [INFO] Two nodes disappear in Galera Cluster! One node is gracefully stopped!"| tee -a $log_file BOOTSTARP_NODE=$(findBootstrapNode) elif [ "$ABNORMAL_SIZE" = "3" ];then echo "`eval date +%Y-%m-%d_%H:%M:%S` [INFO] All nodes went down without proper shutdown procedure!"| tee -a $log_file BOOTSTARP_NODE=$(findBootstrapNode) else echo "`eval date +%Y-%m-%d_%H:%M:%S` [ERROR] No grastate.dat or gvwstate.dat file!"| tee -a $log_file exit 127 fi ### Recover Galera echo "`eval date +%Y-%m-%d_%H:%M:%S` [INFO] The bootstarp node is:"$BOOTSTARP_NODE| tee -a $log_file MYSQL_PID=$(ssh $BOOTSTARP_NODE netstat -ntlp|grep 4567|awk '{print $7}'|awk -F "/" '{print $1}') ssh $BOOTSTARP_NODE /bin/bash << EOF kill -9 $MYSQL_PID mv /var/lib/mysql/gvwstate.dat /var/lib/mysql/gvwstate.dat.bak galera_new_cluster EOF sleep 20 for i in 01 02 03; do if [ "controller$i" = $BOOTSTARP_NODE ];then echo "`eval date +%Y-%m-%d_%H:%M:%S` [INFO] controller$i's mariadb service status:"$(ssh controller$i systemctl status mariadb |grep Active:) | tee -a $log_file else echo "`eval date +%Y-%m-%d_%H:%M:%S` [INFO] controller$i start service:"| tee -a $log_file ssh "controller$i" systemctl start mariadb fi done else echo "`eval date +%Y-%m-%d_%H:%M:%S` [ERROR] Recover Galera Cluster is error!"| tee -a $log_file exit 127 fi ### 3. Check Galera Status sleep 5 WSREP_CLUSTER_SIZE=$(mysql -uroot -p$password_galera_root -e "SHOW STATUS LIKE 'wsrep_cluster_size';"|grep wsrep_cluster_size|awk '{print $2}') echo "`eval date +%Y-%m-%d_%H:%M:%S` [INFO] Galera cluster CLUSTER_SIZE:"$WSREP_CLUSTER_SIZE| tee -a $log_file if [ "${WSREP_CLUSTER_SIZE}" = "3" ]; then echo "`eval date +%Y-%m-%d_%H:%M:%S` [INFO] Galera Cluster is OK!"| tee -a $log_file exit 0 elif [ "$WSREP_CLUSTER_SIZE" = "2" ];then echo "`eval date +%Y-%m-%d_%H:%M:%S` [INFO] One MariaDB nodes is down!"| tee -a $log_file exit 2 elif [ "$WSREP_CLUSTER_SIZE" = "1" ];then echo "`eval date +%Y-%m-%d_%H:%M:%S` [INFO] Two MariaDB nodes is down!"| tee -a $log_file exit 1 else echo "`eval date +%Y-%m-%d_%H:%M:%S` [INFO] All MariaDB nodes is down!"| tee -a $log_file exit 3 fi |
4、Openstack服务启动
4.1 控制节点集群上服务启动
check-or-restart-controller-pcs-cluster.sh,启动pacemaker集群,随之会逐渐启动Haproxy、Mongodb、Redis和Openstack各服务,但所有服务全部启动需要等待一段时间,这里设置了最长等待时间为2min(20*6s),正常情况下,除了haproxy-clone资源存在Stopped状态,如下图,其余资源全部都是Started状态,这里就是通过检查Stopped状态的资源检查controller节点上openstack服务是否正常启动。

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
#!/bin/sh source /root/CloudPlatformOperations/0-set-config.sh WHILE_FLAG=0 wait_start(){ while [ $WHILE_FLAG -lt 20 ] do PCS_RESOURCE_STOP_SIZE=$(pcs resource|grep Stopped|wc -l) HAPROXY_START_FLAG=$(pcs resource|grep -A1 haproxy|grep Started:|wc -l) if [ "${PCS_RESOURCE_STOP_SIZE}" = "1" -a "${HAPROXY_START_FLAG}" = "1" ];then break; fi echo -ne "=>\033[s" echo -ne "\033[40;-20H"$((WHILE_FLAG*5*100/100))%"\033[u\033[1D" let WHILE_FLAG++ sleep 30 done } ### 1. Start pcs cluster pcs cluster start --all ### 2. Wait all start echo "`eval date +%Y-%m-%d_%H:%M:%S` [INFO] Controllers pcs Resources are starting!"| tee -a $log_file wait_start pcs resource ### 3. Check the staus of pcs cluster PCS_RESOURCE_STOP_SIZE=$(pcs resource|grep Stopped|wc -l) HAPROXY_START_FLAG=$(pcs resource|grep -A1 haproxy|grep Started:|wc -l) if [ "${PCS_RESOURCE_STOP_SIZE}" = "1" -a "${HAPROXY_START_FLAG}" = "1" ];then echo "`eval date +%Y-%m-%d_%H:%M:%S` [INFO] All Pcs Resources in controller nodes are started!" | tee -a $log_file exit 0 else echo "`eval date +%Y-%m-%d_%H:%M:%S` [ERROR] Not all the pcs resources in controller nodes are started!"| tee -a $log_file exit 127 fi |
4.2 网络节点集群上服务启动
check-or-restart-networker-pcs-cluster.sh,同控制节点Packemaker集群,不同的是,正常情况下,网络节点集群上所有资源都会正常启动,不存在Stopped状态的资源,如图:
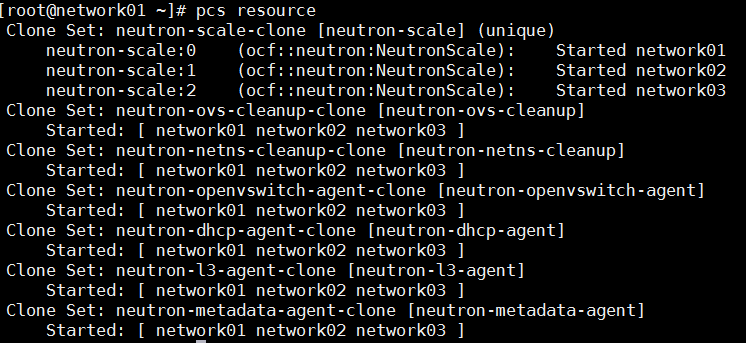
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
#!/bin/sh source /root/CloudPlatformOperations/0-set-config.sh WHILE_FLAG=0 wait_start(){ while [ $WHILE_FLAG -lt 20 ] do PCS_RESOURCE_STOP_SIZE=$(ssh network01 pcs resource|grep Stopped|wc -l) if [ "${PCS_RESOURCE_STOP_SIZE}" = "0" ];then break; fi echo -ne "=>\033[s" echo -ne "\033[40;-20H"$((WHILE_FLAG*5*100/100))%"\033[u\033[1D" let WHILE_FLAG++ sleep 10 done } ### 1. Start pcs cluster ssh network01 pcs cluster start --all ### 2. Wait all start echo "`eval date +%Y-%m-%d_%H:%M:%S` [INFO] Networker Pcs Resources are starting!" wait_start ssh network01 pcs resource ### 3. Check the staus of pcs cluster PCS_RESOURCE_STOP_SIZE=$(ssh network01 pcs resource|grep Stopped|wc -l) if [ "${PCS_RESOURCE_STOP_SIZE}" = "0" ];then echo "`eval date +%Y-%m-%d_%H:%M:%S` [INFO] All pcs resources in network nodes are started!" | tee -a $log_file exit 0 else echo "`eval date +%Y-%m-%d_%H:%M:%S` [ERROR] Not all the pcs resources in network are started!"| tee -a $log_file exit 127 fi |
4.3 计算节点上服务启动
check-or-restart-compute-services.sh,其实计算节点上服务都是开始开机自启动的,这里也做了一遍启动操作。
|
1 2 3 4 5 6 7 8 9 |
#!/bin/sh source /root/CloudPlatformOperations/0-set-config.sh echo "`eval date +%Y-%m-%d_%H:%M:%S` [INFO] Start openstack service in compute nodes!" | tee -a $log_file for ((i=0; i<${#hypervisor_map[@]}; i+=1)); do name=${nodes_name[$i]}; ip=${hypervisor_map[$name]}; ssh root@$ip systemctl start libvirtd.service openstack-nova-compute.service openvswitch.service neutron-openvswitch-agent.service openstack-ceilometer-compute.service done; |
5、Ceph集群状态检测及Rest-api服务启动
5.1 Ceph统一存储集群状态检测
check-ceph-health.sh,检测ceph健康状态是否存在ERROR,如果存在ERROR状态,将无法通过检测。
|
1 2 3 4 5 6 7 8 |
#!/bin/sh IS_ERR=$(ceph health|grep ERR|wc -l) echo "[INFO] Ceph health is $(ceph health)" if [ $IS_ERR = "0" ];then exit 0 else exit 127; fi |
5.2 Ceph-rest-api服务启动
启动ceph-rest-api服务,这里是通过检测ceph-rest-api所绑定的端口进行检测服务是否启动,端口是通过ceph配置文件中配置项动态获取的。
|
1 2 3 4 5 6 7 8 9 10 11 |
#!/bin/sh source /root/CloudPlatformOperations/0-set-config.sh IS_ERR=$(ceph health|grep ERR|wc -l) echo "`eval date +%Y-%m-%d_%H:%M:%S` [INFO] Ceph health is $(ceph health)"| tee -a $log_file if [ $IS_ERR = "0" ];then echo "`eval date +%Y-%m-%d_%H:%M:%S` [INFO] Ceph health is $(ceph health)"| tee -a $log_file exit 0 else echo "`eval date +%Y-%m-%d_%H:%M:%S` [ERROR] Ceph health is $(ceph health)"| tee -a $log_file exit 127; fi |
6、恢复虚拟机的状态
resume_instances_status.sh,利用openstack CLI命令更新虚拟机的状态,主要更新之前状态为“运行中”现在状态为“关机”的虚拟机。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
#!/bin/sh . ~/keystonerc_admin source /root/CloudPlatformOperations/0-set-config.sh ### Get VMs old status sed -i -e 's/^database_host.*/database_host = "'"$virtual_ip"'"/' retrieve_instances_status.py sed -i -e 's/^database_password.*/database_password = "'"$password_galera_root"'"/' retrieve_instances_status.py ### check and resume for line in $(python retrieve_instances_status.py |grep ACTIVE) do ID=$(echo $line|awk -F: '{print $1}') LAST_STATUS=$(echo $line|awk -F: '{print $2}') TMP_FILE=/tmp/_server_info CUR_STATUS=$(nova show $ID|grep status|grep -v "_status"|awk '{print $4}') echo "`eval date +%Y-%m-%d_%H:%M:%S` [INFO] $ID": "${CUR_STATUS} --> ${LAST_STATUS}"| tee -a $log_file if [ "${LAST_STATUS}" = "ACTIVE" -a "$CUR_STATUS" = "SHUTOFF" ];then echo "`eval date +%Y-%m-%d_%H:%M:%S` [INFO] Unconsistent status!Start this VM!"| tee -a $log_file openstack server start $ID fi done |
retrieve_instances_status.py,python脚本,获取管理系统中虚拟机原来的启动状态。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
#!/usr/bin/env python import MySQLdb database_host = '192.168.2.241' database_name = 'cloud' database_username = 'root' database_password = 'a263f6a89fa2' conn= MySQLdb.connect(host = database_host, db = database_name, user = database_username, passwd = database_password, port = 3306, charset = 'utf8') cursor = conn.cursor() cursor.execute('SELECT * FROM cloud.virtual_machine') for row in cursor.fetchall(): print row[0]+':'+row[17] cursor.close() conn.commit() conn.close() |
7、云管理系统Web服务器启动
start-cloud-portal.sh,启动tomcat,检测服务状态。
|
1 2 |
#!/bin/sh /opt/apache-tomcat-7.0.68/bin/startup.sh |
8、一键启动脚本
start-all.sh将上面操作全部汇总(这里使用了绝对路径),如果Rabbitmq、Galera、Pcs Cluster、Ceph等无法完成启动,将无法进行后续的VM状态恢复、管理Portal启动的操作。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
#!/bin/sh source /root/CloudPlatformOperations/0-set-config.sh check_status(){ if [ $? != "0" ];then echo "`eval date +%Y-%m-%d_%H:%M:%S` [ERROR] 启动云平台失败!请联系运维人员!" exit 127 fi } echo -e "\n======= 启动云平台操作开始 =======" | tee -a $log_file echo "操作时间:`date`" | tee -a $log_file echo "操作人:`whoami`" | tee -a $log_file echo `who` >> $log_file ### [Connectity] echo "=== 节点联通性测试 ===" | tee -a $log_file /root/CloudPlatformOperations/bin/check-nodes-connectity.sh check_status ### [Rabbitmq] echo "=== 消息队列集群启动 ===" | tee -a $log_file /root/CloudPlatformOperations/bin/check-or-restart-rabbitmq-cluster.sh check_status ### [Galera] echo "=== 数据库集群启动 ===" | tee -a $log_file /root/CloudPlatformOperations/bin/check-or-recover-galera.sh check_status ### [Pcs cluster] ### 1 controllers echo "=== 管理节点HA集群启动 ===" | tee -a $log_file /root/CloudPlatformOperations/bin/check-or-restart-controller-pcs-cluster.sh check_status ### 2 networker echo "=== 网络节点HA集群启动 ===" | tee -a $log_file /root/CloudPlatformOperations/bin/check-or-restart-networker-pcs-cluster.sh check_status ### [Compute services] echo "=== 计算节点服务启动启动 ===" | tee -a $log_file /root/CloudPlatformOperations/bin/check-or-restart-compute-services.sh ### [Ceph storage cluster] echo "=== 统一存储集群状态检测 ===" | tee -a $log_file /root/CloudPlatformOperations/bin/check-ceph-health.sh check_status ### [Ceph-rest-api] echo "=== 统一存储Rest-api服务启动 ===" | tee -a $log_file /root/CloudPlatformOperations/bin/ceph-rest-api-start.sh check_status ### [Update VMs status] echo "=== 还原虚拟机启动状态 ===" | tee -a $log_file /root/CloudPlatformOperations/bin/resume_instances_status.sh ### [Cloud Portal] echo "=== 云平台管理系统启动 ===" | tee -a $log_file /opt/apache-tomcat-7.0.68/bin/startup.sh echo -e "======= 启动云平台操作结束 =======" | tee -a $log_file |
9、设置开机自启动
Centos7.x设置开机执行脚本
|
1 2 |
chmod +x /etc/rc.d/rc.local echo "/root/CloudPlatformOperations/bin/start-all.sh" >> /etc/rc.d/rc.local |
三、其他说明
源码:https://github.com/zjmeixinyanzhi/CloudPlatformOperations/


codemore code
~~~~